Partie 2 – Introduction à Apache Spark

Apache Spark – Présentation
Apache Spark est une plateforme de traitement sur cluster générique. C’est un moteur de traitement libre, assurant un traitement parallèle et distribué sur des données massives. Il fournit une API de développement pour permettre un traitement en streaming, l’apprentissage automatique ou la gestion de requêtes SQL et demandant des accès répétés sur un grand volume de données. 1
Apache Spark permet de réaliser des traitements par lot (batch processing) ou à la volée (stream processing) et est conçu de façon à pouvoir intégrer tous les outils et technologies Big Data. Par exemple, non seulement Spark peut-il accéder aux sources de données de Hadoop, il peut également tourner sur un cluster Hadoop. Étant donné que Spark n’offre pas de solution de stockage (pas encore en tout cas), il est logique qu’il puisse profiter de la puissance de HDFS (le système de fichiers de Hadoop), tout en offrant lui des performances inégalées pour le traitement en batch, ainsi que d’autres facilités (non offertes par Hadoop Map Reduce) telles que le traitement itératif, interactif et à la volée.
Spark offre des APIs de haut niveau en Java, Scala, Python et R. Il utilise le traitement en mémoire (in-memory processing), en exploitant les ressources combinées du cluster comme si c’était une machine unique.
Apache Spark a été créé en 2009 au laboratoire UC Berkeley R&D Lab (appelé maintenant AMPLab), et est devenu open-source en 2010 avec une licence BSD. En 2013, il a intégré Apache Software Foundation, pour devenir, en 2014, un projet Apache de haut niveau.
Apache Spark – Composants
Apache Spark utilise une architecture en couches, comportant plusieurs composants, dont l’objectif est de permettre de réaliser des traitements performants tout en promettant un développement et une intégration facilitées. Il est né à la base pour pallier les problèmes posés par Hadoop Map Reduce, mais est devenu une entité à lui seul, offrant bien plus que le traitement par lot classique. 1
Voici les composants de Spark:

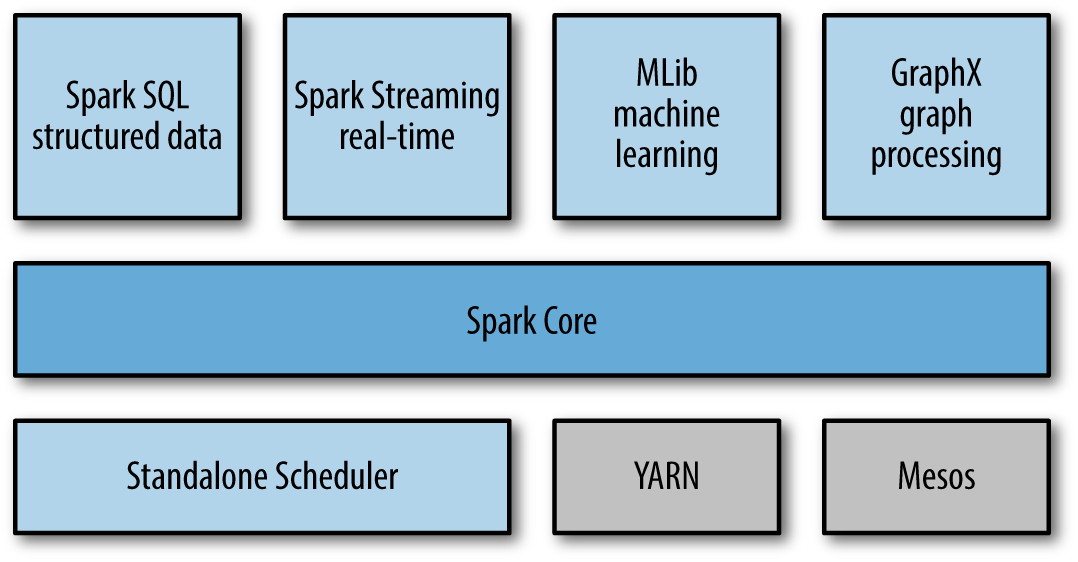
- Spark Core
Spark Core est le point central de Spark, qui fournit une plateforme d’exécution pour toutes les applications Spark. De plus, il supporte un large éventail d’applications. - Spark SQL
Spark SQL se situe au dessus de Spark, pour permettre aux utilisateurs d’utiliser des requêtes SQL/HQL. Les données structurées et semi-structurées peuvent ainsi être traitées grâce à Spark SQL, avec une performance améliorée. - Spark Streaming
Spark Streaming permet de créer des applications d’analyse de données interactives. Les flux de données sont transformés en micro-lots et traités par dessus Spark Core. - Spark MLlib
La bibliothèque de machine learning MLlib fournit des algorithmes de haute qualité pour l’apprentissage automatique. Ce sont des libraries riches, très utiles pour les data scientists, autorisant de plus des traitements en mémoire améliorant de façon drastique la performance de ces algorithmes sur des données massives. - Spark GraphX
Spark Graphx est le moteur d’exécution permettant un traitement scalable utilisant les graphes, se basant sur Spark Core.
Architecture de Spark
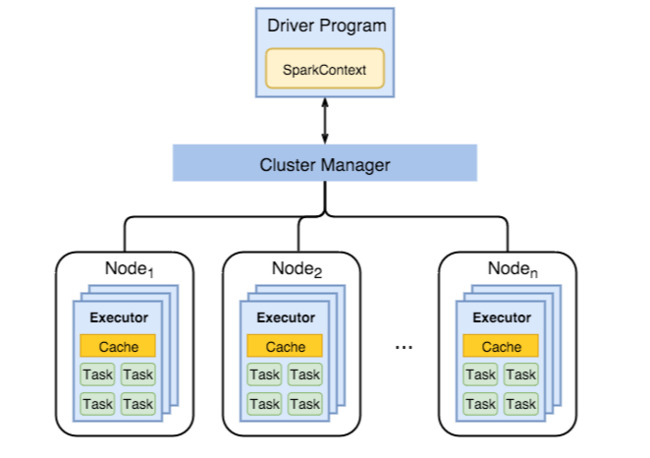
Les applications Spark s’exécutent comme un ensemble indépendant de processus sur un cluster, coordonnés par un objet SparkContext dans le programme principal, appelé driver program. 2
Pour s’exécuter sur un cluster, SparkContext peut se connecter à plusieurs types de gestionnaires de clusters (Cluster Managers):
- Sur le gestionnaire autonome de Spark, qui est inclus dans Spark, et qui présente le moyen le plus rapide et simple de mettre en place un cluster.
- Sur Apache Mesos, un gestionnaire de cluster général qui peut aussi tourner sur Hadoop Map Reduce.
- Sur Hadoop YARN, le gestionnaire de ressources de Hadoop 2.
- Sur Kubernetes, un système open-source pour l’automatisation du déploiement et la gestion des applications conteneurisées.
Ces gestionnaires permettent d’allouer les ressources nécessaires pour l’exécution de plusieurs applications Spark. Une fois connecté, Spark lance des exécuteurs sur les noeuds du cluster, qui sont des processus qui lancent des traitements et stockent des données pour les applications. Il envoie ensuite le code de l’application (dans un fichier JAR ou Python) aux exécuteurs. Spark Context envoie finalement les tâches à exécuter aux exécuteurs.
Il est à noter que:
- Chaque application a son lot d’exécuteurs, qui restent actifs tout au long de l’exécution de l’application, et qui lancent des tâches sur plusieurs threads. Ainsi, les applications sont isolées les unes des autres, du point de vue de l’orchestration (chaque driver exécute ses propres tâches), et des exécuteurs (les tâches des différentes applications tournent sur des JVM différentes). Ceci implique également que les applications (ou Jobs) Sparks ne peuvent pas échanger des données, sans les enregistrer sur un support de stockage externe.
- Spark est indépendant du gestionnaire de cluster sous-jacent. Il suffit de configurer Spark pour utiliser ce gestionnaire, il peut gérer ses ressources en même temps que d’autres applications, même non-Spark.
- L’application principale (driver) doit être à l’écoute des connexions entrantes venant de ses exécuteurs.
Caractéristiques de Spark
Spark est connu pour avoir plusieurs caractéristiques qui en font l’une des plateformes les plus utilisées dans le domaine des Big Data. Nous citons: 1
- Performance de traitement: Il est possible de réaliser une vitesse de traitement très élevée avec Spark sur des fichiers volumineux qui peut être jusqu’à 100x meilleur que Hadoop Map Reduce, par exemple, et ceci grâce à des mécanismes tel que la réduction du nombre de lectures écritures sur le disque, la valorisation du traitement en mémoire et l’utilisation des mémoires cache et RAM pour les données intermédiaires.
- Dynamicité: Il est facile de développer des applications parallèles, grâce aux opérateurs haut niveau fournis par Spark (allant jusqu’à 80 opérateurs).
- Tolérance aux Fautes: Apache Spark fournit un mécanisme de tolérance aux fautes grâce aux RDD. Ces structures en mémoire sont conçues pour récupérer les données en cas de panne.
- Traitements à la volée: L’un des avantages de Spark par rapport à Hadoop Map Reduce, c’est qu’il permet de traiter les données à la volée, pas uniquement en batch.
- Évaluations Paresseuses (Lazy Evaluations): Toutes les transformations faites sur Spark RDD sont paresseuses de nature, ce qui veut dire qu’elles ne donnent pas de résultat direct après leur exécution, mais génèrent un nouvel RDD à partir de l’ancien. On n’exécute effectivement les transformations qu’au moment de lancer une action sur les données. Nous allons détailler cet aspect plus tard dans le cours.
- Support de plusieurs langages: Plusieurs langages de programmation sont supportés par Spark, tel que Java, R, Scala et Python.
- Une communauté active et en expansion: Des développeurs de plus de 50 entreprises sont impliqués dans le développement et l’amélioration de Spark. Ce projet a été initié en 2009 et est encore en expansion.
- Support d’analyses sophistiquées: Spark est fourni avec un ensemble d’outils dédiés pour le streaming, les requêtes interactives, le machine learning, etc.
- Intégration avec Hadoop: Spark peut s’exécuter indépendamment ou sur Hadoop YARN, et profiter ainsi de la puissance du système de fichiers distribué Hadoop HDFS.
Limitations de Spark
Spark a plusieurs limitations, tel que : 1
- Pas de support pour le traitement en temps réel: Spark permet le traitement en temps-presque-réel, car il utilise le traitement en micro-lot plutôt que le traitement en streaming.
- Problèmes avec les fichiers de petite taille: Spark partitionne le traitement sur plusieurs exécuteurs, et est optimisé principalement pour les grands volumes de données. L’utiliser pour des fichiers de petite taille va rajouter un coût supplémentaire, il est donc plus judicieux dans ce cas d’utiliser un traitement séquentiel classique sur une seule machine.
- Pas de système de gestion des fichiers: Spark est principalement un système de traitement, et ne fournit pas de solution pour le stockage des données. Il doit donc se baser sur d’autres systèmes de stockage tel que Hadoop HDFS ou Amazon S3.
- Coûteux: En tant que système de traitement en mémoire, le coût d’exécuter Spark sur un cluster peut être très élevé en terme de consommation mémoire.
- Nombre d’algorithmes limité: Malgré la disponibilité de la bibliothèque MLlib, elle reste limitée en termes de nombre d’algorithmes implémentés.
- Latence: La latence de Spark pour l’exécution de Jobs à la volée est plus élevée que d’autres solutions de traitement en streaming tel que Flink.