
BIG DATA: Définition
• La notion de Big Data est un concept s’étant popularisé en
2012 pour traduire le fait que les entreprises sont confrontées à
des volumes de données à traiter de plus en plus considérables
et présentant un fort enjeux commercial et marketing.
• Ces Grosses Données en deviennent difficiles à travailler avec
des outils classiques de gestion de base de données.
• Il s’agit donc d’un ensemble de technologies, d’architecture,
d’outils et de procédures permettant à une organisation de
très rapidement capter, traiter et analyser de larges
quantités et contenus hétérogènes et changeants, et d’en
extraire les informations pertinentes à un coût accessible
BIG DATA: Caractéristiques
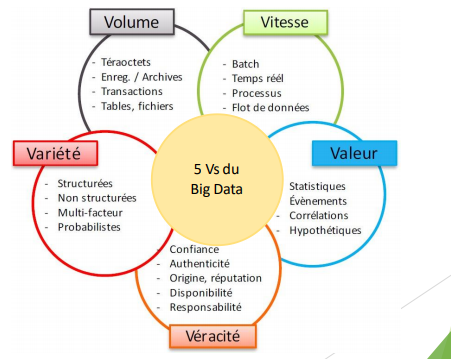
• COUVERTURE DE CINQ DIMENSIONS – 5Vs (1/2)
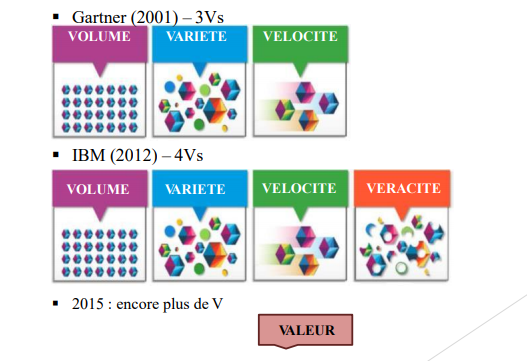
BIG DATA: Caractéristiques
COUVERTURE DE CINQ DIMENSIONS – 5Vs (2/2)
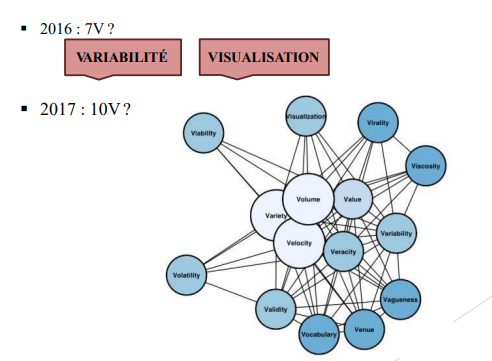
• COUVERTURE DE CINQ DIMENSIONS – 5Vs (1/7)
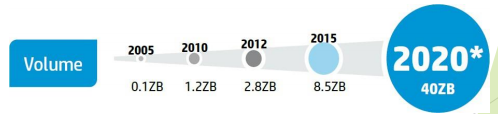
– Volume (1/2)
• Croissance sans cesse des données à gérer de tout type, souvent en teraoctets voir
en petaoctets.
• Chaque jour, 2.5 trillions d’octets de données sont générées.
• 90% des données créées dans le monde l’ont été au cours des 2 dernières
années (2014).
• Prévision d’une croissance de 800% des quantités de données à traiter d’ici à 5 ans
BIG DATA: Caractéristiques
Cours Big Data – 2019
• COUVERTURE DE CINQ DIMENSIONS – 5Vs (2/7)
– Volume (2/2)
• 4,4 zettaoctets de données
= 4,4 trillion de gigaoctets
• En 2013, il y a autant de données que les étoiles connues dans tout l’univers.
• 44 zettaoctets de données
= 44 milliards gigaoctets
• 62 fois le nombre de tous les sables dans
toutes les plages de la terre.
• COUVERTURE DE CINQ DIMENSIONS – 5Vs (3/7)
– Variété
• Traitement des données sous forme structurée (bases de données structurée,
feuilles de calcul venant de tableur, …) et non structurée (textes, sons, images,
vidéos, données de capteurs, fichiers journaux, medias sociaux, signaux,…) qui
doivent faire l’objet d’une analyse collective.

COUVERTURE DE CINQ DIMENSIONS – 5Vs (4/7)
– Vitesse (Velocity)
• Utilisation des données en temps réel (pour la détection de fraudes, analyse des
données, …).
• Fait référence à la vitesse à laquelle de nouvelles données sont générées et la
vitesse à laquelle les données sont traitées par le système pour être bien analysées.
• La technologie nous permet maintenant d’analyser les données pendant qu’elles
sont générées, sans jamais mettre en bases de données.
• Streaming Data
➢ des centaines par seconde
• 100 Capteurs
➢ dans chaque voiture moderne pour la surveillance
COUVERTURE DE CINQ DIMENSIONS – 5Vs (5/7)
– Véracité
• Fait référence à la qualité de la fiabilité et la confiance des données.
• Données bruités, imprécises, prédictives, …
• La génération des données par Spambots est un exemple digne de confiance.
➢ L’élection présidentielle de 2012 au Mexique avec de faux comptes Twitter.
• DES MILLIONS DE DOLLARS $ PARAN
➢Ce que la pauvre qualité des données coute pour
l’économie des Etats-Unis.
• 1 à 3 CHEFS D’ENTREPRISE
➢ Ne font pas confiance à l’information qu’ils utilisent.
• COUVERTURE DE CINQ DIMENSIONS – 5Vs (6/7)
– Valeur
• La démarche Big Data n’a de sens que pour atteindre des objectifs stratégiques de
création de valeur pour les clients et pour l’entreprise; dans tous les domaines
d’activité : commerce, industrie, services …
• Le succès d’un projet Big Data n’a d’intérêt aux utilisateurs que s’il apporte de la
valeur ajoutée et de nouvelles connaissances.
• DIVERSITE ET VOLUME DES SOURCES DE DONNEES (1/4)
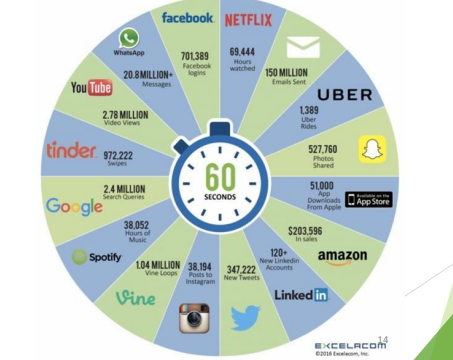

BIG DATA: Généralités
• DIVERSITE ET VOLUME DES SOURCES DE DONNEES (3/4)
– Outils numériques plus performants et plus connectés:
ordinateurs et smartphones
– Open Data
• Réseaux sociaux: facebook
• Données d’administrations publiques
– Internet des Objets
• RFID (cartes de transport, codes bar, …)
• Ericsson a estimé le nombre d’objets connectés dans le monde à 50 milliards en
2020 (12 milliards en 2013)
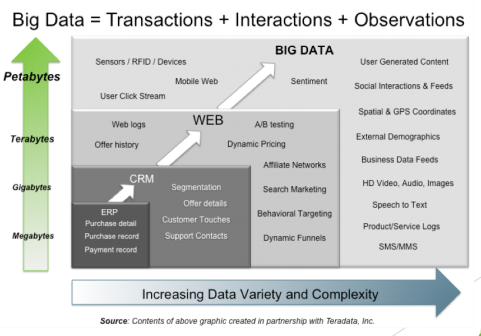
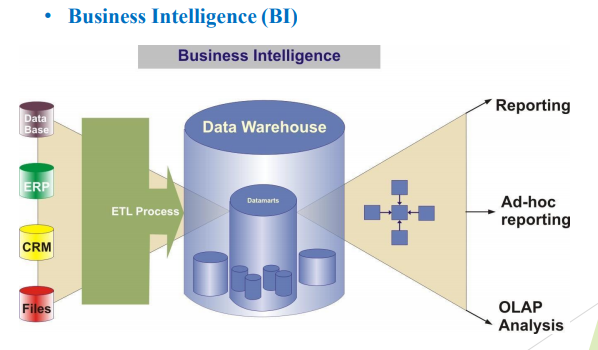
Quel est le problème posé par ces énormes quantités de données?
▪ Auparavant, quand les systèmes d’application de gestion de base de données
ont été réalisés, ils ont été construits avec une échelle à l’esprit (limité). Même
les organisations n’ont pas été préparées à l’échelle que nous produisons
aujourd’hui.
▪ Comme les exigences de ces organisations ont augmenté au fil du temps, ils
doivent repenser et réinvestir dans l’infrastructure. Actuellement, le coût des
ressources impliquées dans l’extension de l’infrastructure, s’augmente avec
un facteur exponentiel.
▪ De plus, il y aurait une limitation sur les différents facteurs tels que la taille de
la machine, CPU, RAM, etc. qui peuvent être mis à l’échelle (scaled up). Ces
systèmes traditionnels ne seraient pas en mesure de soutenir l’échelle requise
par la plupart des entreprises
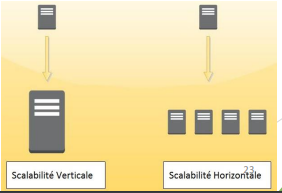
ADAPTABILITE
▪ Dans ce nouveau contexte, les méthodes de traitement de ces données
(capture, stockage, recherche, partage, analyse, visualisation) doivent être
redéfinies car l’ensemble de ces données deviennent difficilement
manipulables par les outils classiques
Comment le Big Data gère ces situations complexes? (1/3)
• La plupart des outils et des frameworks de Big Data sont construits en gardant
à l’esprit les caractéristiques suivantes:
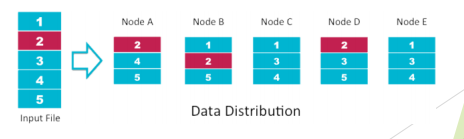
– La distribution des données: Le grand ensemble de données est divisé en
morceaux ou en petits blocs et réparti sur un nombre N de nœuds ou de machines.
Ainsi les données sont réparties sur plusieurs noeuds et sont prêtes au traitement
parallèle. Dans le monde du Big Data, ce type de distribution des données est réalisé à
l’aide d’un Système de Fichiers Distribués – DFS (Distributed File System).
Comment le Big Data gère ces situations complexes? (2/3)
– Le traitement en parallèle : Les données distribuées obtiennent la puissance de N
nombre de serveurs et de machines dont les données résident. Ces serveurs
travaillent en parallèle pour le traitement et l’analyse. Après le traitement, les
données sont fusionnées pour le résultat final recherché. (Actuellement ce
processus est réalisé par MapReduce de Google qui sera détaillé dans une section
ultérieure).
– La tolérance aux pannes: En général, nous gardons la réplique d’un seul bloc (ou
chunk) de données plus qu’une fois. Par conséquent, même si l’un des serveurs ou
des machines est complètement en panne, nous pouvons obtenir nos données à
partir d’une autre machine ou d’un autre « data center ». Encore une fois, nous
pouvons penser que la réplication de données pourrait coûter beaucoup d’espace.
Mais voici le quatrième point de la rescousse.
Comment le Big Data gère ces situations complexes? (3/3)
– L’utilisation de matériel standard : La plupart des outils et des frameworks Big
Data ont besoin du matériel standard pour leur travail. Donc nous n’avons pas
besoin de matériel spécialisé avec un conteneur spécial des données « RAID ».
Cela réduit le coût de l’infrastructure totale.
– Flexibilité, évolutivité et scalabilité : Il est assez facile d’ajouter de plus en plus
de nœuds dans le cluster quand la demande pour l’espace augmente. De plus, la
façon dont les architectures de ces frameworks sont faites, convient très bien le
scénario de Big Data
• Exemple Simple (1/4)
– Analyser une data set de 1TB

Exemple Simple (2/4)
– Temps d’accès.
Exemple Simple (3/4)
Temps d’accès (lecture) > 2h
+
Temps de calcul ~ 1h
+
Bande passante du réseau etc
> 3h
Exemple Simple (4/4)
– Division d’un fichier de 1TB en 100 bloques égaux
– Lecture Parallèle
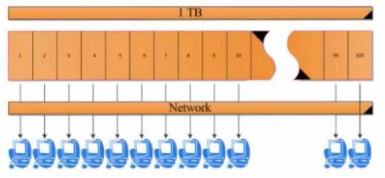
Temps de lecture = 150 min / 100 < 2min
Temps de calcul = 60 min / 100 < 1 min
PERSPECTIVES ET DOMAINES D ’APPLICATION
• Les perspectives d’utilisation de ces données sont énormes, notamment pour
l’analyse d’opinions politiques, de tendance industrielles, la génomique, la
lutte contre la criminalité et la fraude, les méthodes de marketing publicitaire
et de vente etc …
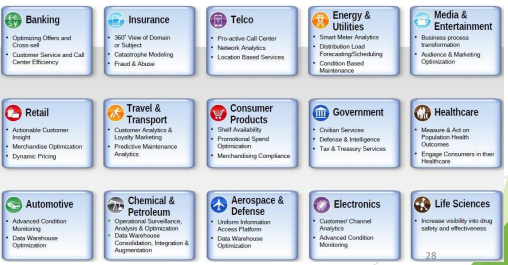
• Cas d’utilisation : Santé (1/2)
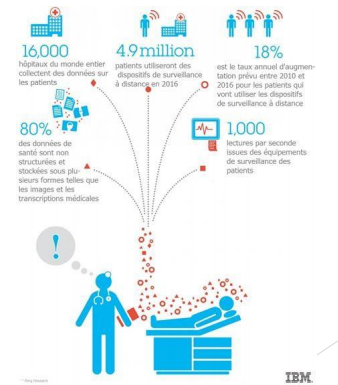
Analyse des données globales des patients et des résultats pour comparer
l’efficacité des différentesinterventions.
• Analyse des résultats de santé d’une population pour prévoir les maladies et
les épidémies, savoir les causes environnementales et prendre les prévention
nécessaire dans les stages primaires.
• Déploiement de systèmes d’aide à la décision clinique pour améliorer
l’efficacité et la qualité des opérations.
• Télésurveillance des patients. La collecte de données pour les patients
souffrants de maladies chroniques et l’analyse des données résultant pour
surveiller la conformité et pour améliorer les futures options de médicaments
et de traitement.
Cas d’utilisation : Marketing
• Plus d’intelligence pour plus de ventes.
• Analyse prédictive : En analysant l’historique des achats du client ou les
fichiers Logs qui contiennent les pages visitées, l’entreprise peut prévoir ce
que le client cherche et les mettre dans les zones des offres et publicités afin
d’augmenter les achats.
• Analyse des sentiments : De Nombreuses sociétés utilisent les échanges sur
les réseaux sociaux comme le reflet de l’opinion publique. Celle-ci devient une
nouvelle source d’informations en temps réel directement fournie par le
consommateur. Les questions d’e-réputation « à quoi est associée mon image ?
» ou « comment est accueilli le nouveau produit que je viens de lancer ? »
peuvent être analysées avec ces données. Le Big Data permet de prendre le
pouls quasiment en direct, mesurer l’impact de sa marque, savoir comment est
perçue la société par le public et anticiper les mauvaises critiques.
Analyse des comportements : L’analyse du comportement des clients en
magasin permet d’améliorer l’aménagement du magasin, le mix produit et la
disposition des produits dans les rayons et sur les étagères. Les dernières
innovations ont également permis de suivre les habitudes d’achat (compter le
nombre de pas effectués et le temps passé dans chaque rayon du magasin),
géolocaliser en temps réel les clients,…. Les données issues des tickets de
caisse, captées depuis longtemps, peuvent maintenant être analysées et
révèlent les habitudes d’achat des clients.
• Cas d’utilisation : Analyse de tweets en temps réel
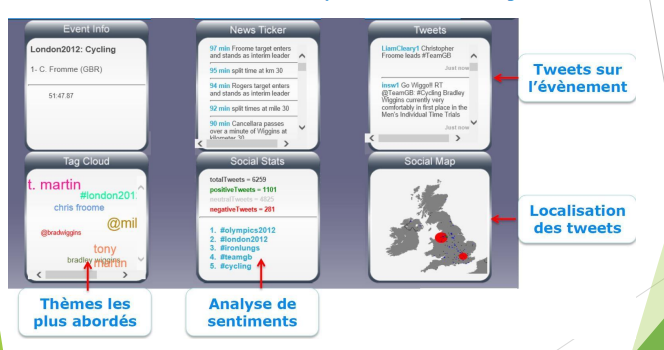 L’analyse de Big Data a joué un rôle important dans la campagne de réélection de Barack Obama, notamment pour analyser les opinions politiques de
L’analyse de Big Data a joué un rôle important dans la campagne de réélection de Barack Obama, notamment pour analyser les opinions politiques de
la population.
• Depuis l’année 2012, le Département de la défense américain investit
annuellement sur les projets de Big Data plus de 250 millions de dollars.
• Le gouvernement américain possède six des dix plus puissants
supercalculateurs de la planète.
• La National Security Agency est actuellement en train de construire le Utah
Data Center. Une fois terminé, ce data center pourra supporter des yottaoctets
d’information collectés par la NSA surinternet.
• En 2014, SIGMA conseil a utilisé le Big Data pour donner l’estimation du
résultat de vote préliminaire en Tunisie.
Cas d’utilisation : Sport (1/2)
La première source de données recueillie s’appuie sur des capteurs intégrés
aux protège-tibias ou aux chaussures. Ces minuscules composants remontent
des informations biométriques sur les joueurs:
▪ la distance parcourue
▪ les vitesses en sprint
▪ les accélérations
▪ le nombre de ballons touchés
▪ le rythme cardiaque, etc.
→ A terme et quand l’analyse en temps réel sera réellement possible, on peut très
bien imaginer qu’une alerte remonte lorsqu’un joueur fatigue afin que
l’entraîneur le remplace.
Une deuxième source de récolte de données provient de caméras installées en
hauteur autour du terrain. Tous les déplacements des joueurs et leurs positions
les uns par rapport aux autres sont ainsi filmés et enregistrés. Lors de son
débriefing, le tacticien peut ainsi comparer plusieurs fois par match la position
géométrique de son équipe au moment des temps forts, quand l’équipe se
montre offensive, s’ouvre des occasions et marque des buts.
▪ Le tacticien a également la capacité d’analyser le comportement de son équipe
en fonction de la réaction de l’équipe concurrente. Ces données peuvent
ensuite être agrégées avec d’autres sources telles que l’historique des matchs
joués ou les données recueillies pendant les entraînements.
Cas d’utilisation : Sécurité publique
▪ Aujourd’hui, avec le Big Data, la vidéosurveillance va beaucoup plus loin : elle permet
d’analyser automatiquement les images et les situations, de croiser les informations, et
d’envoyer des alertes.
▪ Cette analyse de vidéo avancée est utilisée en particulier pour :
o la sécurité du trafic (routier, ferroviaire, maritime et aérien)
o la protection des espaces et des bâtiments publics
o la sécurité personnelle.
▪ Il est aujourd’hui possible à travers l’analyse des images vidéo de faire de :
o la reconnaissance d’objets et de mouvements
o la lecture de plaques minéralogiques
o la détection de véhicule non autorisé
o la reconnaissance faciale
o l’auto-surveillance avec possibilité de déclenchement d’alertes ou autres actions
automatisées.
▪A titre d’exemple la ville de Londres avait, quant à elle, mis en place un système de
reconnaissance faciale lors des jeux olympiques de 2012 organisés dans la capitale, afin de
lutter contre le terrorisme pour lequel l’alerte était à son maximum.
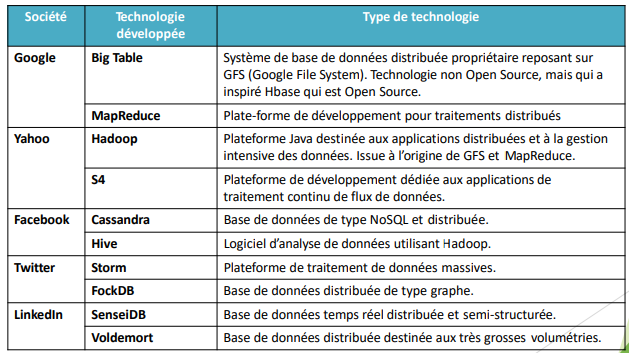
Les grands acteurs du web tel que Google, Yahoo, Facebook,
Twitter, LinkedIn … ont été les premiers à être confrontés à des
volumétries de données extrêmement importantes et ont été à
l’origine des premières innovations en la matière portées
principalement sur deux types de technologies :
1. Les plateformes de développement et de traitement
des données (GFS, Hadoop, Spark,…) [chapitre 2-3-4]
2. Les bases de données (NoSql) [chapitre 5-6]
Historique : Big Data, Google : Le système de fichierGFS
• Pour stocker son index grandissant quelle solution pour Google ?
1. Utilisation d’un SGBDR ?
➢ Problème de distribution des données
➢ Problème du nombre d’utilisateurs
➢ Problème de Vitesse du moteur de recherche
système propriétaire : GFS ( Google File
Système) en 2003
• Historique : Big Data, Google : Le système de fichierGFS
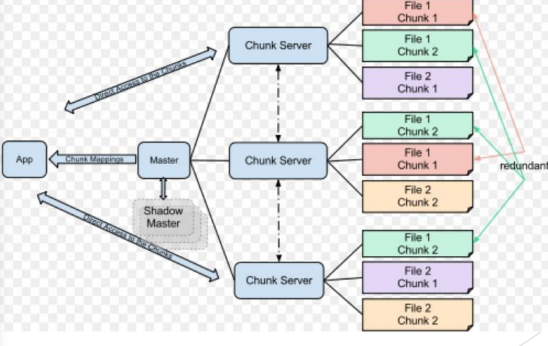
BIG DATA: Historique
La notion de Big Data est intimement lié à la capacité de traitements de
gros volumes.
– Le premier Article a été publié en 2004 : Jeffrey Dean and Sanjay
Ghemawat
➢ MapReduce : Simplified Data Processing on Large Clusters
– C’est un algorithme inventé par Google, Inc afin de distribuer des
traitements sur un ensemble de machines avec le systèmeGFS.
– Google possède aujourd’hui plus de 1 000 0000 de serveurs
interconnectés dans le monde
BIG DATA: Les Acteurs de l’Open
Source
• Les contributeurs de l’implémentation Libre et Open Source :
• Ces entreprises ont décidé d’ouvrir leurs développements internes
au monde Open Source.
• Un certains nombre de ces technologies comme « Hadoop» et
« Spark » font partie de la fondation Apache et ont été intégrés
aux offres de « Big Data » des grands acteurs tel que IBM,
Oracle, Microsoft, EMC …
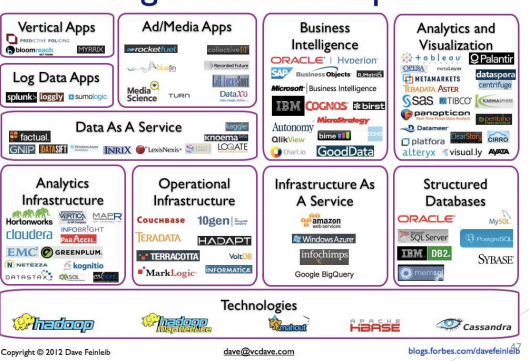
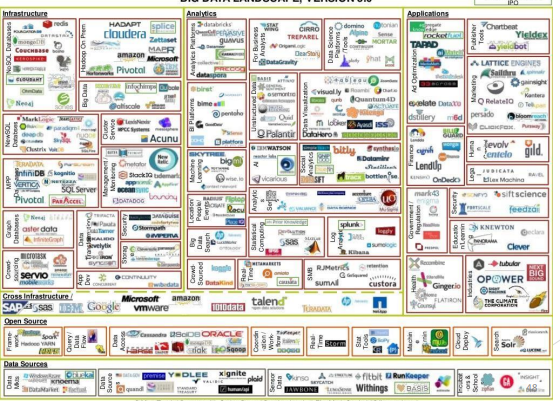
BIG DATA: Plateforme – Technologies – Outils
BIG DATA: Plateforme – Technologies – Outils
Processing
– Hadoop, Hive, Pig, mrjob, Caffeine
• NoSQL Databases
– Hbase, MongoDB, Vertica, Cassandra, Neo4j, etc.
• Servers
– EC2, Google App Engine, Elastic, Beanstalk, Heroku
• Analytics
– R, SAS, Python scikit-learn, Spark MLLib, Apache Mahout
• Search
– Solr/Lucene, ElasticSearch


Nous sommes actuellement dans l’ère de la production massive de données.
D’une part, les applications génèrent des données issues des logs, des réseaux
de capteurs, des rapports de transactions, des traces de GPS, etc. et d’autre part,
les individus produisent des données telles que des photographies, des vidéos,
des musiques ou encore des données sur l’état de santé (rythme cardiaque,
pression ou poids).
• Un problème se pose alors quant au stockage et à l’analyse des données. La
capacité de stockage des disques durs augmente mais le temps de lecture croît
également. Il devient alors nécessaire de paralléliser les traitements en stockant
sur plusieurs machines.
• Plusieurs solutions, inspirées des solutions de Google, ont été proposées.
Hadoop est la solution la plus répondue au monde de BigData. Cette solution
sera détaillée dans le chapitre suivant.



